
Outline
ちょっと古いけど読めていなかった Meta-Learning with Memory-Augmented Neural Networks を読んだのでメモ。
従来の gradient-based network は学習に大量のデータを必要とするため、新種のデータが入力された場合に対応するのが難しいが、Memory-Augmented Neural Networks (MANN) はこの状況に対応できそうだからやってみたという論文。
タイトルにあるようにこの論文では Meta-Learning を行うことを軸に議論を展開している。
この論文において Meta-Learning は以下の用に解釈される。
Although the term has been used in numerous senses, meta-learning generally refers to a scenario in which an agent learns at two levels, each associated with different time scales.
Given its two-tiered organization, this form of meta- learning is often described as “learning to learn.”
つまり、Meta-Learning では短期的な学習と長期的な学習の2種類の学習を組み合わせて学習が行われる。
短期的な学習では1つのタスクについての学習が行われ、長期的な学習ではこのような短期的な学習の仕方、つまりタスク一般についての学習の仕方が学習される。
現状、Meta-Learning は Recurrent Neural Networks (RNN) など記憶能力をもつ Neural Networks (NN) によりある程度行えるらしい。
しかし、Scalable な Meta-Learning を行うには以下の2つの制約を満たす必要がある。
- 記憶される情報が静的に保存され、かつそれらの情報に個別にアクセスできる。
- パラメーターの数と記憶できる情報の量に依存関係が無い。
これらの条件は通常の RNN などでは普通満たされないが、MANN はこれを満たすため、この論文では MANN の一種である Neural Turing Machine (NTM) を用いて Meta-Learning を行っている。
以降、図は特に指定がない限り元論文から引用。
Meta-Learning Task Methodology
Optimization
Neural Network を使った機械学習においては通常、あるデータセット \(D\) についてパラメータ \(\theta\) を、学習コスト \(\cal L\) を最小化するように調整する。
一方 Meta-Learning では以下の式 (\ref{meta_learn_func}) のように、データセットの分布 \(p(D)\) に対して同様の最適化を図る。
Tasks
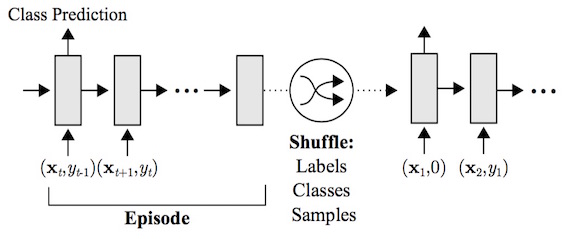
またこの論文におけるタスクは、系列型のデータセット \(D = {d_t}^{T}_{t=1} = {({\bf x}_t, y_t)}^{T}_{t=1}\) (\({\bf x_t}\) は入力、\(y_t\) は入力に対する適切な正解ラベル) について行われるが、Few-shot learning を行うため少しトリッキー (下の図参照)。
なお、下の図には Class Prediction と書かれているが分類だけでなく回帰も同様に扱う。
すなわち、時間 \(t\) においてモデルは \({\bf x_t}\) および \(y_{t-1}\) を入力として受け取り、\({\bf x_t}\) に対応する正しいラベル \(y_t\) を出力するように学習を行う。よって \(t = 0\) での \(y_{t-1}\) を \(null\) としたとき、モデルが入力として受けとる系列データは \(({\bf x_1}, null), ({\bf x_2}, y_1), ..., ({\bf x_T}, y_{T-1})\)、これに対してモデルが理想的に出力する系列データは \(y_1, y_2 , ..., y_t\) である。
なおこのタスクで扱うデータセットは一つではなく、モデルが大量のデータから各データセットの \({\bf x_t}\) に対する \(y_t\) を長期的な学習の中で憶えてしまって純粋な Few-shot learning が行えなくなるのを防ぐため、下の図のように \({\bf x_t}\) に対する \(y_t\) は各データセットの学習開始時に毎回シャッフルされる。
そのため、\(t = 1\) における \(y_1\) は正解しようのないラベルとなる。
Memory-Augmented Model
MANN は近年研究され始めたモデルであり、主に NTM と Memory Networks に基づくモデルが幾つか提案されている。
この論文では NTM を用いて Few-shot learning を行っているが、オリジナルの NTM に対して Least Recently Used Access を認識できるよう改良を加えている。
詳細は時間の都合上省略。(時間のあるときに追記。)
Experimental Results
この論文では Few-shot learning に関して分類、回帰問題のそれぞれについて、Omniglot および sampled functions from a Gaussian process という2つのデータセットを用いて実験を行っている。
本記事では時間の都合上この内、Omniglot、つまり分類問題に関してのみ書く。
Omniglot は以下の図に示すような手書き文字の画像データセット。 (Paper : Human-level concept learning through probabilistic program introduction より引用。)
1600 以上のクラスがあり、各クラス毎に幾つかのサンプルがある。
この論文ではそれらを更に 90, 180, 270 度回転させて data augmentation を行っている。

タスクは上の Tasks に書いたように行われる。
入力された画像がどのクラスのものかということも大事だが、どのクラスでないかを認識して消去法的にクラス分類も行うこともできる。
学習は 100,000 データセットに対して行われ、各データセットは Omniglot からランダムに 5 つ選ばれたクラスに対してランダムなラベルを付与することで構成される。
その他詳細は論文参照。
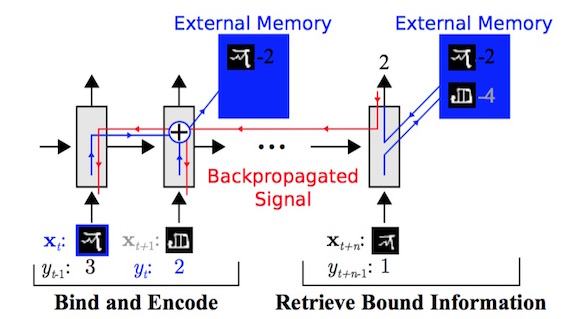
下の図が実際の動作イメージ。
前半でクラス2の画像が2であることが判明しており、Few-shot learning ができる場合後半で同じクラスの画像を正しく2と分類できている。
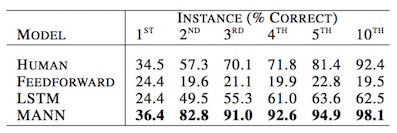
そして下の表が実験結果。
HUMAN, LSTM, MANN はデータ入力されるにつれて基本的には精度が上がっており、MANN が非常に良い性能を出している。
なお、FEEDFORWARD は feed-forward RNN を指す。
人間が 1st で 1/5 の確率でしか当たらないはずのラベルを 34.5% で当てているは懐疑的なのでもしかしたら実験設定について何か勘違いしているのかも...。
一応、これよりも高い精度で 1st を分類している MANN は educated guessing (学習により良いあてずっぽう推測ができるようになった?) と書かれているがラベルはデータセットごとに
よくわかっていない...
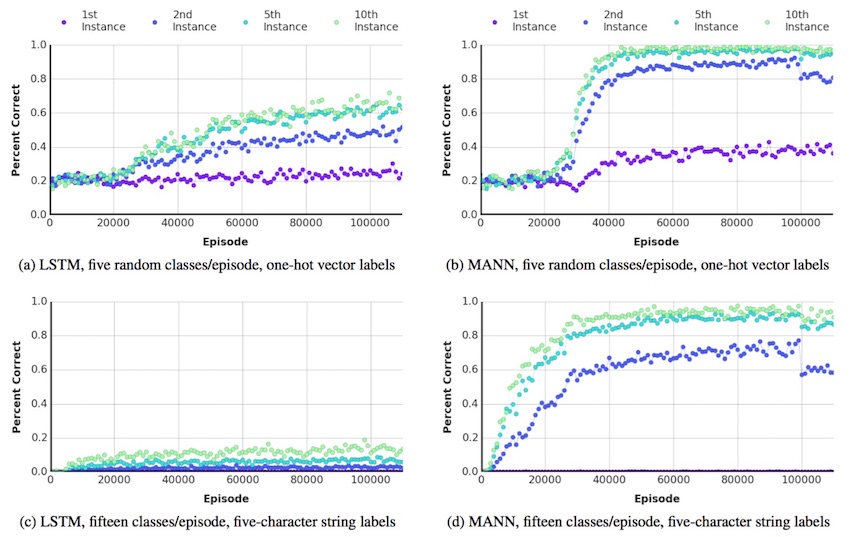
下の図は LSTM および MANN の学習曲線。a, b は出力に onehot-vector を用いたもので、c, d は出力を文字列で行ったもの。文字列で行った場合、組み合わせによって大量のパターンを表現できるためクラス数が増えるに従いネットワークサイズが大きくなり学習が難しくなる onehot vector に比べてより多くのクラスを扱える。
以上!
Comments
comments powered by Disqus